
VHDL: Concetto di entity.
Un entity è un’astrazione di un dispositivo che può rappresentare un sistema completo, una scheda, un chip, una funzione o una porta logica. Una dichiarazione di entity descrive l’I/O di un progetto e può includere anche parametri utilizzati per customizzare l’entity stessa.
Un’architettura descrive le funzioni di un’entity. Un’architettura può contenere qualunque combinazione dei seguenti tipi di descrizione:
•Behavioural;
•Structural;
•Dataflow.
Nell’immagine un esempio di listato che mostra l’implementazione di un behavioral.

Viene chiamata descrizione comportamentale per il modo algoritmico in cui viene descritta l’architettura. La descrizione comportamentale viene indicata, a volte, come descrizione ad alto livello a causa dell’assomiglianza con i linguaggi di programmazione ad alto livello. Piuttosto che specificare la struttura o la netlist di un circuito, è possibile specificare un insieme di istruzioni che, quando eseguite in sequenza, descrivono il funzionamento, o il comportamento, dell’entità, o di parte di essa. Il vantaggio di una descrizione ad alto livello è che non è necessario focalizzarsi sull’implementazione a livello di gate.
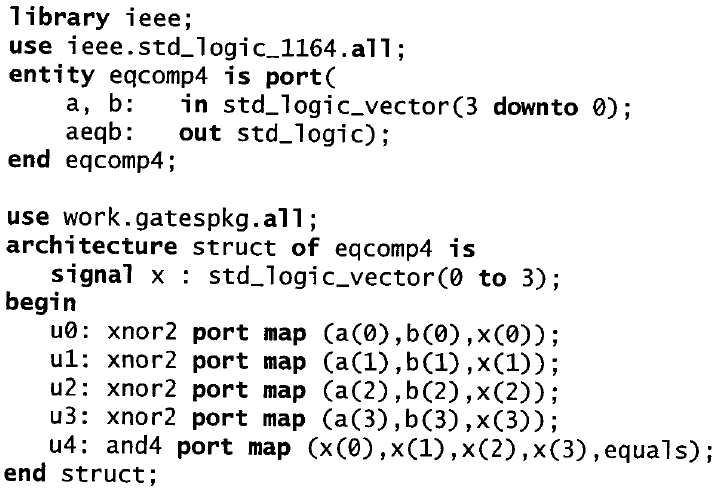
Il listato riportato sotto è un esempio di descrizione di tipo dataflow di un comparatore a quattro bit.

Questa è un’architettura di tipo dataflow perché specifica come i dati vengono trasferiti da segnale a segnale e da ingresso a uscita senza ricorrere all’utilizzo di istruzioni sequenziali. La differenza principale con la descrizione di tipo behavioral è che una utilizza i processi e l’altra no. Però entrambe le descrizioni non sono di tipo strutturale. Conviene utilizzare le descrizioni di tipo dataflow nel caso in cui è possibile scrivere semplici equazioni, istruzioni di assegnamento condizionato (WHEN-ELSE), o istruzioni di assegnamento selettivo (WITH-SELECT-WHEN), piuttosto che algoritmi completi. D’altra parte, quando è necessario utilizzare strutture annidate, sono preferibili le istruzioni sequenziali.
Descrizione strutturale.
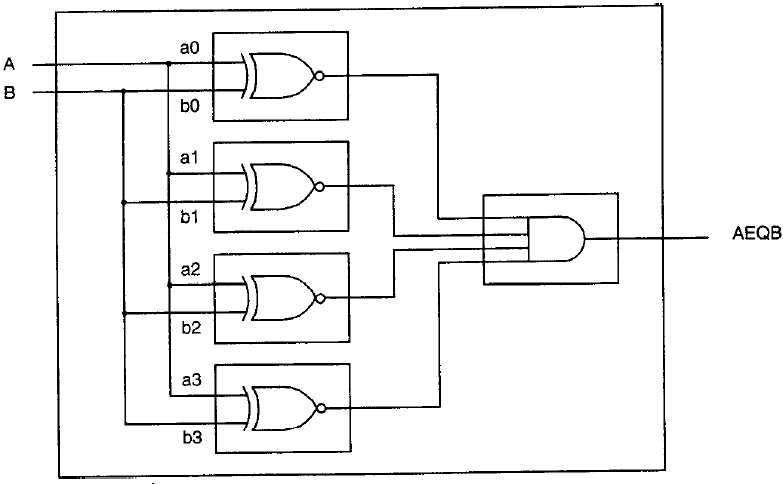
nel listato sottostante c’è la descrizione strutturale di un comparatore a 4 bit.
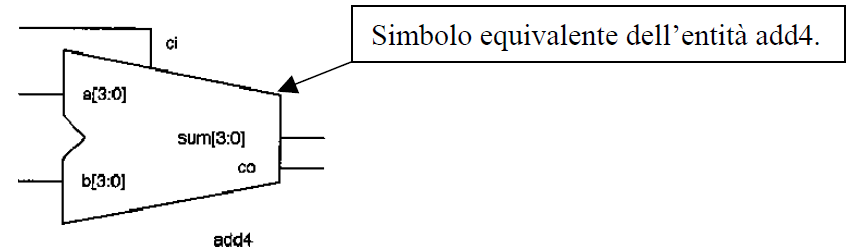
La descrizione strutturale consiste di una netlist VHDL. Questa netlist è molto simile alla netlist di uno schematico: I componenti sono elencati e connessi insieme mediante segnali. I progetti strutturali sono di tipo gerarchico. Nella figura (1) è riportato lo schematico del comparatore a quattro bit descritto nel listato precedente.
Dichiarazione di Entity
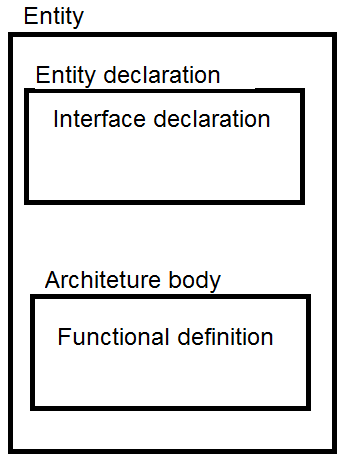
Una dichiarazione di entity descrive gli ingressi e le uscite del progetto. Può anche descrivere parametri costanti. La dichiarazione di entity è analoga al simbolo di uno schematico che descrive le connessioni di un componente con il resto del progetto.
La struttura ho questo incapsulamento. è messa in evidenza la relazione tra un progetto, la dichiarazione di entità e l’architeture body.
Porte
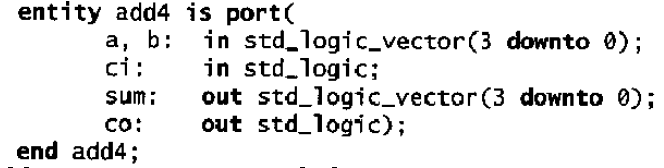
Ogni segnale di I/O in una dichiarazione di entity è chiamato porta, ed è analogo ad un pin nel simbolo di uno schematico. Ad una porta possono essere assegnati valori o essere usata all’interno delle espressioni. L’insieme delle porte definite in una entity è chiamato dichiarazione delle porte. Ogni porta che viene dichiarata deve avere un nome, una direzione (modo) e un data type.MODI: i modi descrivono la direzione in cui un dato è trasferito attraverso la porta. Il modo può assumere uno dei quattro valori: IN, OUT, INOUT e BUFFER. Se il modo non viene specificato allora la porta di default è in modo IN.L’utilizzo dei modi è il seguente:
•IN. I dati fluiscono solo dentro l’entità. Il driver per una portadi modo IN è al di fuori dell’entità. Il modo IN viene utilizzato principalmente per gli ingressi di clock, gli ingressi di controllo (come load, reset e enable) e per gli ingressi unidirezionali dei dati.
•OUT. I dati fluiscono solo verso le porte di uscita dell’entità. Ildriver per una porta di modo OUT è contenuto all’interno dell’entità. Il modo OUT non permette la retroazione perché tale porta non è considerata leggibile dall’interno dell’entità. Il modo OUT è utilizzato per le uscite.
•BUFFER. Per utilizzare internamente la retroazione (cioè per utilizzare una porta come driver all’interno dell’architettura), è necessario dichiarare la porta in modalità BUFFER, o dichiarare un segnale separato da utilizzare all’interno dell’architettura come segnale interno. Una porta che viene dichiarata in modalità BUFFER è simile ad una porta che è dichiarata come OUT, eccetto che permette di effettuare internamente una retroazione. La modalità BUFFER non consente ad una porta di essere bidirezionale perché non consente alla porta di essere pilotata dall’esterno dell’entità. Vanno fatte due considerazioni addizionali sull’utilizzo della modalità BUFFER: (1) una porta in modalità BUFFER non consente di essere pilotata da più driver; (2) una porta in modalità BUFFER può essere connessa solo ad un segnale interno o ad un’altra porta di modalità BUFFER di un’altra entità. Non può essere connessa a nessun altra porta in nodalitàOUT o INOUT di un’altra entità, eccetto che passando attraverso un segnale interno. La modalità BUFFER è utilizzata per porte che devono essere leggibili all’interno dell’entità.
•INOUT. Per segnali bidirezionali è necessario dichiarare le porte di modo INOUT, questa modalità permette ai dati di fluire dentro o fuori dall’entità. In altre parole, il driver del segnale può essere all’interno o all’esterno dell’entità. Ilmodo INOUT permette anche le retroazioni interne. Il modo INOUT è in grado di sostituire tutti gli altri modi. Cioè, IN, OUT e BUFFER possono essere sostituiti dal modo INOUT (questa opzione è sconsigliabile in quanto riduce molto la leggibilità del codice del progetto).
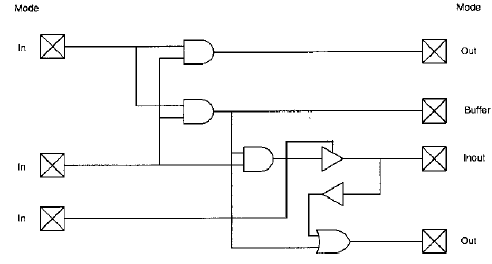
modalità delle porte e le loro possibilità di collegamento con l’interno e l’esterno dell’entità.
Tipi associati alle porte.
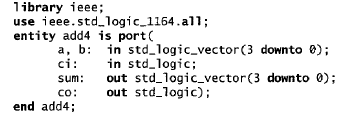
Oltre a specificare i nomi e i modi delle porte è necessario anche dichiarare il tipo delle porte. I tipi più utili e meglio supportati per la sintesi forniti dal package IEEE std_logic_1164 sono i tipi STD_LOGIC e gli array derivati da questi. Come implica il nome, standard logicv uole essere un tipo standard utilizzato per descrivere i circuiti. La dichiarazione dei tipi deve essere resa visibile all’entità per mezzo delle istruzioni LIBRARY e USE, come riportato del listato sotto:
Il VHDL è un linguaggio fortemente tipizzato, cioè i dati di differenti tipi base non possono essere assegnati gli uni agli altri senza utilizzare una funzione di conversione di tipo. Di seguito è riportata una descrizione di alcuni dei tipi che più comunemente si possono incontrare.
Tipi scalari. I tipi scalari possiedono un ordine che permette l’applicazione di operatori relazionali tra loro. Ci sono tre principali categorie di operatori scalari: enumerativi, interi, floating.
Tipi enumerativi. Un tipo enumerativo è una lista di valori che un oggetto di un dato tipo può assumere. E’ possibile definire la lista dei valori. I tipi enumerativi sono utilizzati spesso per definire lo stato delle macchine sequenziali:
TYPE states IS (idle, preamble, data, jam, nofsd, error);
Un segnale può essere definito del tipo enumerativo appena dichiarato:
SIGNAL current_state: states;
Come tipo scalare, il tipo enumerativo è ordinato. L’ordine in cui i valori sono elencati nella dichiarazione del tipo, definiscono la loro relazione. Il valore a sinistra è il più piccolo di tutti gli altri valori. Ogni valore è più grande di quello a sinistra e più piccolo di quello a destra.
Ci sono altri due tipi enumerativi, predefiniti dallo standard IEEE 1076, che sono particolarmente utili per la sintesi: BIT e BOOLEAN. Essi sono definiti come segue:
TYPE boolean IS (FALSE, TRUE);
TYPE bit IS (‘0’,’1’);
Lo standard IEEE 1164 definisce un tipo addizionale e diversi sottotipi che sono utilizzati consistentemente come standard sia per la simulazione che per la sintesi. Il tipo STD_LOGIC è definito come segue:
TYPE std_logicIS ( ‘U’, –Uninitialized
‘X’, –Forcing Unknown
‘0’, –Forcing 0
‘1’, –Forcing 1
‘Z’, –High impedance
‘W’, –Weak Unknown
‘L’, –Weak 0
‘H’, –Weak 1
‘-’, –Don’tcare );
I valori ‘0’, ’1’, ‘L’ e ‘H’ sono valori logici che sono supportati dalla sintesi. I valori ‘Z’ e ‘-’ sono anch’essi supportati dalla sintesi per i driver three state e per i valori don’t care. I valori ‘U’, ‘X’ e ‘W’ non sono supportati dalla sintesi.
Nella maggior parte dei progetti viene utilizzato il tipo STD_LOGIC. E’ più versatile del tipo BIT perché fornisce il valore di alta impedenza ‘Z’ e il valore don’t care ‘-’. Lo standard IEEE 1164 definisce array di STD_LOGIC come STD_LOGIC_VECTOR.
Una nota finale sul tipo STD_LOGIC: sebbene gli identificatori non sono case-sensitive, l’interpretazione dei valori letterali come ‘Z’ e ‘L’ è case-sensitive. Questo significa che ‘z’ non è equivalente a ‘Z’.
•Tipi interi. Nel VHDL sono predefiniti gli interi e gli operatori relazionali ed aritmetici sugli interi. Gli strumenti software che processano il VHDL devono supportare gli interi nel range da –2.147.483.647, -(231-1) a 2.147.483.647, (231-1). Un segnale o una variabile che è di tipo intero e che deve essere sintetizzata nel circuitologico deve essere limitata in valore cioè:
VARIABLE a: INTEGER RANGE –255 TO 255;
Non tutti i sistemi di sintesi per logiche programmabili sono ingrado di trattare valori con segno.
•Tipo floating. I valori del tipo floating sono utilizzati per approssimare i numeri reali. Il solo tipo floating point predefinito e il REAL, che include al minimo il range tra –1.0E38 e +1.0E38. I tipi floating spesso non sono supportati dai programmi di sintesi (in particolare quelli per logiche programmabili) a causa della grande quantità di risorse richieste per l’implementazione delle operazioni aritmetiche tra loro.
Tipi composti. Ai tipi scalari può essere assegnato solo un valore. I tipi composti possono invece assumere più valori contemporaneamente. I tipi composti sono i tipi ARRAY e i tipi RECORD.
•Tipi array. Un oggetto di tipo array consiste di elementi multipli dello stesso tipo. I tipi di array più comunemente usati sono quelli predefiniti dagli standard IEEE 1076 e 1164:

Questi tipi sono comunemente utilizzati per indicare i bus.
Quando si utilizzano le stringhe di bit, è possibile utilizzare una notazione opportuna per indicare se i bit delle stringhe sono specificati in binario, in ottale o in esadecimale. Se tuttavia la stringa è specificata in binario può essere assegnata solo ad un oggetto di tipo BIT_VECTOR e non ad un oggetto di tipo STD_LOGIC_VECTOR. Per i formati ottale ed esadecimale occorre trasformare la stringa binaria nel formato desiderato ad esempio:
a <= X”7A”;
Richiede che asia di 8 bit, dove a può essere un BIT_VECTOR o uno STD_LOGIC_VECTOR il cui valore diventa “01111010”. La notazione per indicare le cifre esadecimali è Xseguita dalla cifra esadecimale tra virgolette, per le ottalil’indicatore è Omentre per quelle binarie è B.
•Tipi record. Un oggetto di tipo record ha elementi multipli di tipi differenti. I singoli campi possono essere referenziati con il nome dell’elemento, come nell’esempio riportato sotto.


Operatori Logici.
Gli operatori logici fondamentali in ambito booleano in VHDL sono i classici: AND,OR,NAND,XOR,XNOR,NOT
In linea di massimo i compilatori li accettano sia se scritti in maiuscolo che in minuscolo. Sono operatori predefiniti per i tipi BIT e BOOLEAN o per i vettori di BIT o BOOLEAN. Lo standard IEEE 1164 estende questi operatori per il tipo STD_LOGIC e i suo vettore STD_LOGIC_VECTOR.
Questi operatori non hanno un ordine di precedenza: sono richieste le parentesi.
X <= (a OR b) AND c
Se eliminiamo le parentesi la sintassi viene accettata ma la valutazione dell’espressione potrebbe risultare errata. Questo è errato -> X <= a OR b AND c
risulta valutata correttamente l’espressione: X <= a OR (b AND c)
Si deve quindi prestare particolare attenzione.
Operatori Relazionali.
Gli operatori relazionali sono utilizzati per testare l’uguaglianza, la disuguaglianza e l’ordinamento.
= Operatore di uguaglianza
/= Operatore di disuguaglianza
< Minore
>,>= Maggiore e maggiore uguale
<,<= Minore e minore uguale
Gli operatori = e /= sono definiti per tutti i tipi di dati finora incontrati,
Gli operatori >,>=, < e <= sono definiti per i tipi scalari o gli array con un range di valori discreto.
Gli array sono uguali solo se le loro lunghezze sono equivalenti e tutti gli elementi corrispondenti sono uguali.
Il risultato degli operatori relazionali è booleano (cioè, è vero o falso).
I tipi di operandi in un’operazione relazionale devono essere uguali.
with – select -when
Sono operatori di assegnamento selettivo dei segnali.
WITH selection_signal SELECT
signal_name <= value_a WHEN value_1_of_selection_signal,
value_b WHEN value_2_of_selection_signal,
value_c WHEN value_3_of_selection_signal,
value_x WHEN ultimo_valore_della_selezione_signali;
Al segnale signal_name viene assegnato un valore in base al valore corrente del segnale selection_signal. T utti i valori di selection_signal devono essere elencati nell’istruzione WHEN e tali valori sono mutuamente esclusivi.
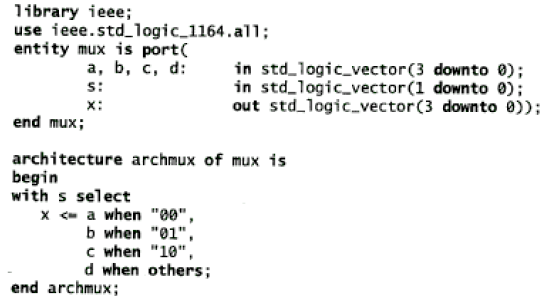
Mentre la condizione WHEN nell’istruzione WITH-SELECT-WHEN deve specificare valori mutuamente esclusivi del segnale di selezione, la condizione WHEN in un’istruzione WHEN-ELSE può specificare qualunque semplice espressione.
Se le condizioni in un’istruzione WHEN-ELSE non sono mutuamente esclusive, la priorità più alta viene assegnata alla prima condizione WHEN elencata. Le priorità delle successive condizioni WHEN sono assegnate in base all’ordine di apparizione.
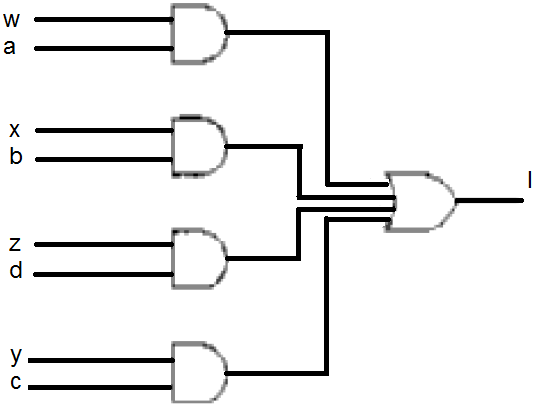
Nell’immagine la rete di selezione dei segnali w,x,y e z in base ai segnali mutuamente esclusivi a,b,c e d.
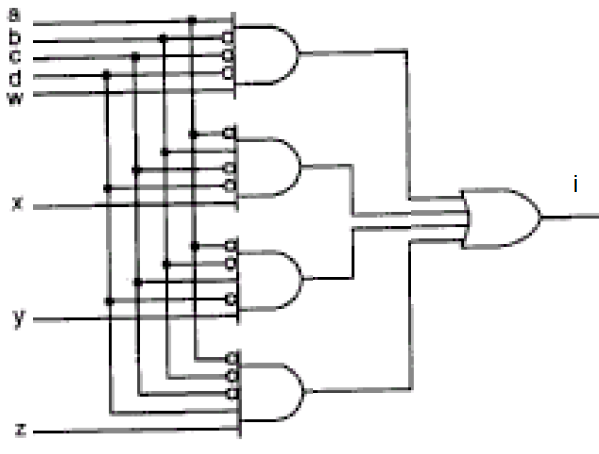
Nell’immagine sopra la selezione dei segnali w,x,y e z in base ai segnali non mutuamente esclusivi a,b,c e d.
IF – THEN – ELSE
L’istruzione IF-THEN-ELSE è utilizzata per selezionare un insieme di istruzioni da
eseguire in base alla valutazione di una condizione o un’insieme di condizioni.
IF (condition) THEN
do something;
ELSE
do something different;
END IF;
Se la condizione specificata viene trovata vera, vengono eseguite le istruzioni che
seguono la parola chiave THEN. Se la condizione viene trovata falsa, vengono eseguite
le istruzioni dopo ELSE. L’insieme di istruzioni viene chiuso da END IF.
Dato che le istruzioni sequenziali vengono eseguite nell’ordine di apparizione, i seguenti
processi sono funzionalmente equivalenti

Con entrambi i processi, step assume il valore ‘1’ se addr è maggiore di 0F hex, e ‘0’ se è minore o uguale al valore indicato.
il processo:

non descrive la stessa logica perché non è assegnato né un valore di default né un valore di ELSE al segnale step. Il processo not_similar implica che step deve mantenere il suo valore se addr è minore o uguale a 0F hex. Questa viene chiamata memoria implicita. Così, una volta che è stato asserito, step rimarrà sempre al valore asserito come mostrato nella prossima figura e definito dalla seguente equazione:
step=addr(3)*addr(2)*addr(1)*addr(0) + step
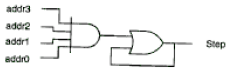
nella figura un esempio di memoria implicita.
Se non si vuole che il valore di step venga memorizzato è necessario includere un valore di default o completare l’istruzione IF-THEN con un ELSE.
L’istruzione IF-THEN_ELSE può essere ulteriormente espansa includendo ELSIF per specificare ulteriori condizioni.
La sintassi di questa operazione è

Costrutto Case – When
L’istruzione CASE-WHEN viene utilizzata per specificare un insieme di istruzioni da eseguire in base al valore di un segnale selezione. L’istruzione CASE-WHEN può essere utilizzata, per esempio, in modo equivalente all’istruzione WITH-SELECT-WHEN.
La sintassi è:

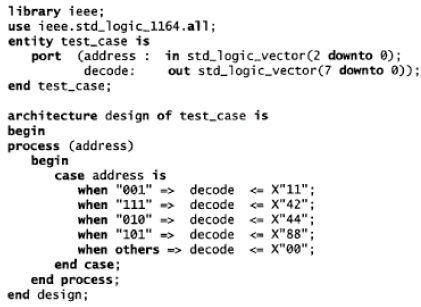
Di seguito viene riportato un esempio di applicazione dell’istruzione CASE-WHEN alla
creazione di un decodificatore di indirizzi.
Logica sincrona Flip-Flop e Registri
implementazione VHDL di un FLIP FLOP tipo D.

descrizione e simbolo di un flip flip di tipo D che memorizza sul fronte positivo del clock
implementazione in VHDL di un FLIP FLOP dipo T.
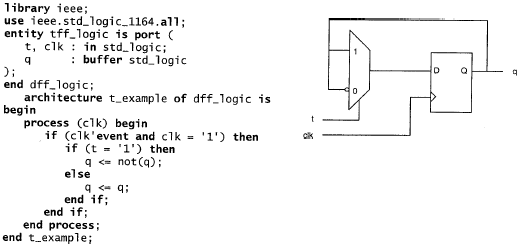
descrizione e simbolo di un flip flip di tipo T (toggle) che memorizza sul fronte positivo del clock
implementazione di un REGISTRO a 8 bit in VHDL.

Il registro di 8 bit con memorizzazione del dato sul fronte positivo del clock.
WAIT – UNTIL
E’ possibile descrivere il comportamento di un filp flop di tipo D anche mediante l’istruzione WAIT-UNTIL invece di IF (clk’ ENVENT AND clk=1):

Questo processo non utilizza una sensitivity list, ma inizia con l’istruzione WAIT. Un processo che utilizza un’istruzione WAIT non può avere una sesitivity list (l’istruzione WAIT definisce implicitamente la sensitivity list). Per i circuiti che devono essere sintetizzati, l’istruzione WAIT-UNTIL deve essere la prima del processo. A causa di questo, la logica sincrona descritta utilizzando l’istruzione WAIT non può essere resettata in modo asincrono.
Sensibilità ai fronti dei segnali.
Le funzioni rising_edge e falling_edge rendono il sistema reattivo ai rispettivi fronti dei segnali.
Il package STD_LOGIC_1164 definisce le funzioni RISING_EDGE e FALLING_EDGE per rilevare i fronti di salita e di discesa dei segnali.
Una di queste funzioni può essere utilizzata per sostituire l’espressione (clk’EVENT AND clk=‘1’) se il segnale clk è di tipo STD_LOGIC.
Queste funzioni a volte sono preferite dai progettisti perché nelle simulazioni la funzione RISING_EDGE assicura che la transizione avviene tra ‘0’ e ‘1’ enon qualche altra transizione come ad esempio tra ‘U’ e ‘1’.

Descrizione di un FLIP FLOP tipo D utilizzando la funzione RISING_EDGE.
Reset e preset nella logica sincrona
Lo standard VHDL non richiede che un circuito venga inizializzato o resettato. Lo standard specifica che per la simulazione, a meno che un segnale non sia esplicitamente inizializzato, un segnale viene inizializzato al valore ‘left del suo tipo. Così, il tipo STD_LOGIC verrà inizializzato a ‘U’, e un bit verrà inizializzato a ‘0’.
Nell’hardware, questo non è sempre vero, non tutti i dispositivi si inizializzano nello stato di reset, ma in uno stato privo di significato.
E’ possibile descrivere il reset e il preset di un dispositivo mediante una semplice modifica del codice VHDL come segue in cui nel flip flop di tipo D è presente un reset di tipo asincrono:

La sensitivity list indica che questo processo è sensibile ai cambiamenti di clke reset. Se il segnale di resetviene messo a ‘1’, al segnale qviene assegnato il valore ‘0’ qualunque sia il valore di clk.
Per descrivere un preset al posto di un reset, è possibile modificare la sensitivity list e scrivere.
![]()
invece che:
![]()
E’ possibile anche resettare(o presettare) un flip flop in modo sincrono ponendo la condizione di reset (o preset) all’interno della porzione del processo che descrive la logica che è sincrona con il clock, come segue in un esempio che riguarda un FLIP FLOP D (con reset sincrono)

Generalmente la logica sincrona richiede risorse hardware addizionali rispetto a reset e presetasincrono.
In VHDL è possibile anche descrivere una combinazione di reset e/o preset sincroni/asincroni. Per esempio, un registro a 8 bit può essere resettato a 0 ogni volta che il segnale resetva a ‘1’, e può essere inizializzato con tutti 1 e caricato dal fronte di salita del clock, come riportato nel listato che segueper un registro a 8 bit con reset asincrono e inizializzazione sincrona:

Buffer three-state e segnali bidirezionali.
Descrizione comportamentale di un buffer tree-state.
I valori che un segnale three-state può assumere sono ‘0’, ‘1’ e ‘Z’, e sono supportati tutti dal tipo STD_LOGIC.
L’utilizzo dei buffer three-state viene illustrato mediante l’esempio di un contatore a 8 bit caricabile:

Il processo chiamato oes è utilizzato per descrivere l’uscita three-state del contatore. Questo processo indica semplicemente che se oeviene messo a ‘1’, il valore di cnt viene assegnato a cnt-oute se oeviene messo a ‘0’, l’uscita di questo dispositivi viene posta in alta impedenza. Il processo è sensibile al cambiamento di entrambe le variabili oe e cnt, perché un cambiamento in entrambi i segnali provoca un cambiamento nell’uscita cnt_out. Il processo oes descrive il comportamento di un buffer three-state.
![]()
Il controllo dei buffer three-state può essere descritto anche con l’istruzione WHEN-ELSE. Nel listato che segue, che è una versione modificata del contatore a 8 bit, è stata aggiunta un’uscita addizionale, collision, che viene messa a ’1’ quando i segnali load e enable sono contemporaneamente posti a ‘1’.

Segnali bidirezionali.
I segnali bidirezionali possono essere descritti con una piccola modifica dei listati del contatore visti in precedenza.

In questo caso il contatore viene caricato con il valore corrente sui pin associati con l’uscita del contatore, questo significa che il valore caricato quando loadviene posto a ‘1’ potrebbe essere il valore precedente del contatore oppure un valore posto sui pin da un altro dispositivo, a seconda dello stato di oe.
for–generate
Se si volesse utilizzare un componente chiamato threestate, precedentemente creato, per implementare un buffer three-state per un bus di 32 bit, al posto di istanziare 32 buffer è possibile utilizzare l’istruzione FOR-GENERATE come segue:

Questo tipo di istruzione viene implementato nella parte delle istruzioni concorrenti di un’architettura, non all’interno di un process. L‘istruzione FOR-GENERATE richiede una label; in questo caso gen_label.
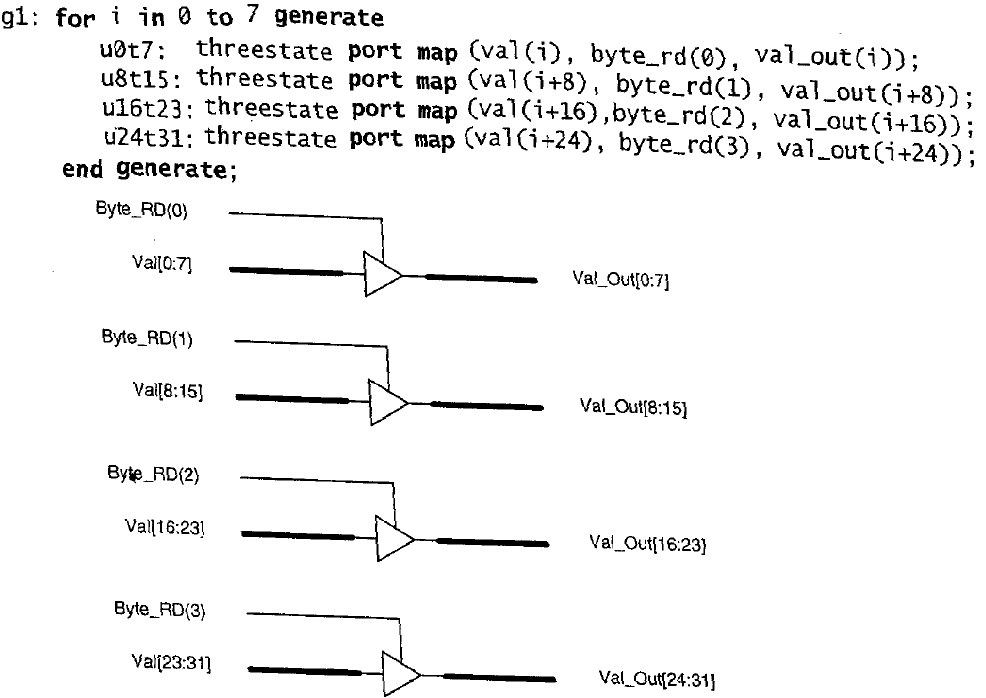
E’ possibile utilizzare schemi più complicati dell’istruzione FOR-GENERATE in cui sono presenti assegnamenti di tipo condizionato, come ad esempio:

Il listato include l’istruzione IF-THEN. Quando viene utilizzata insieme all’istruzione FOR-GENERATE, l’istruzione IF-THEN non può includere un ELSE o un ELSIF.
Convertire i buffer three-state in multiplexer
Alcune FPGA contengono al loro interno dei buffer three-state, altre no. Tuttavia, i progetti che utilizzano bus three-state possono essere convertiti in progetti che utilizzano i multiplexer. Alcuni strumenti di sintesi possono fare questo automaticamente. La conversione dei buffer three-state in multiplexer è illustrata nella figura che segue:
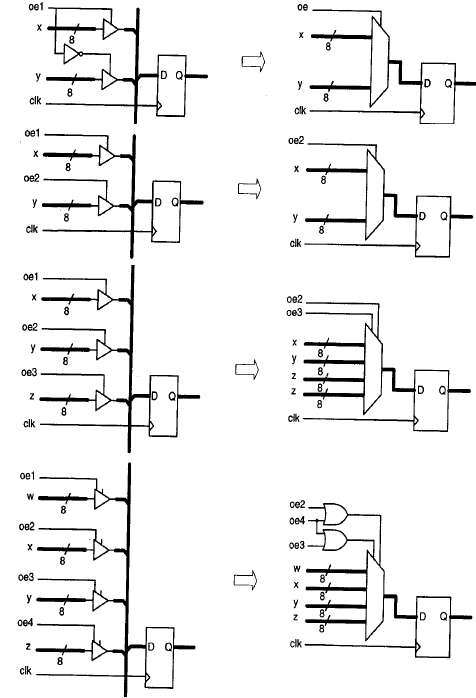
I Cicli
I cicli sono utilizzati per implementare operazioni ripetitive, e possono essere sia cicli FOR che cicli WHILE. Il ciclo FOR esegue un numero predeterminato di iterazioni in base ad un valore di controllo. Il ciclo WHILE continua l’esecuzione di un’operazione finché non si verifica una condizione logica di controllo. Si consideri per esempio il ciclo che esegue il reset asincrono della FIFO
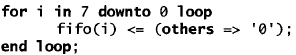
Questo ciclo che scandisce tutti gli 8 STD_LOGIC_VECTOR che compongono la FIFO, inizializza ogni elemento del vettore a ‘0’. In un ciclo FOR, la variabile del ciclo viene dichiarata automaticamente. Al posto del ciclo FOR potrebbe essere utilizzato anche un ciclo WHILE, ma questo richiede delle dichiarazioni, delle inizializzazioni e un incremento della variabile di ciclo addizionali, come mostrato nell’esempio sotto:

Iterazioni condizionate.
L’istruzione NEXT viene utilizzata per saltare un operazione in base al verificarsi di una determinata condizione. Si supponga per esempio che quando il segnale rst viene posto ad ‘1’, tutti i registri della FIFO siano resettati eccetto che per il registro FIFO(4):

Oppure può essere scritto utilizzando un ciclo WHILE:

Uscita dai cicli.
L’istruzione EXIT viene utilizzata per uscire dai cicli, e può essere utilizzata per testare una condizione illegale. La condizione deve essere verificata all’istante della compilazione. Si supponga, per esempio, che la FIFO sia un componente che viene istanziato in un progetto gerarchico. Si supponga inoltre che la profondità della FIFO venga definita per mezzo di un parametro di tipo GENERIC. Si vuole uscire dal ciclo quando la profondità della FIFO diventa più grande di un valore predeterminato. Ad esempio:

Il frammento di codice riportato sopra può essere riscritto come:

Progetto di una FIFO
Si vuole progettare una FIFO con profondità di 8 parole di 9 bit. Descrizione dei segnali:
Quando il segnale rd viene posto a ‘1’, l’uscita della FIFO, data_out, deve essere abilitata.
Quando rd è a ‘0’, l’uscita deve essere posta in alta impedenza.
Quando il segnale di write wrviene posto a ‘1’ si vuole scrivere in uno dei registri di 9 bit.
I segnali rdinc e wrincsono utilizzati per incrementare i puntatori di lettura e scrittura che indicano quale registro leggere e scrivere.
Rdptrclr e wrptrclr resettano i puntatori di lettura e scrittura e li indirizzano al primo registro della FIFO.
Data_in è il dato che deve essere caricato in uno dei registri.La figura mostra uno schema a blocchi della FIFO a 9 bit.
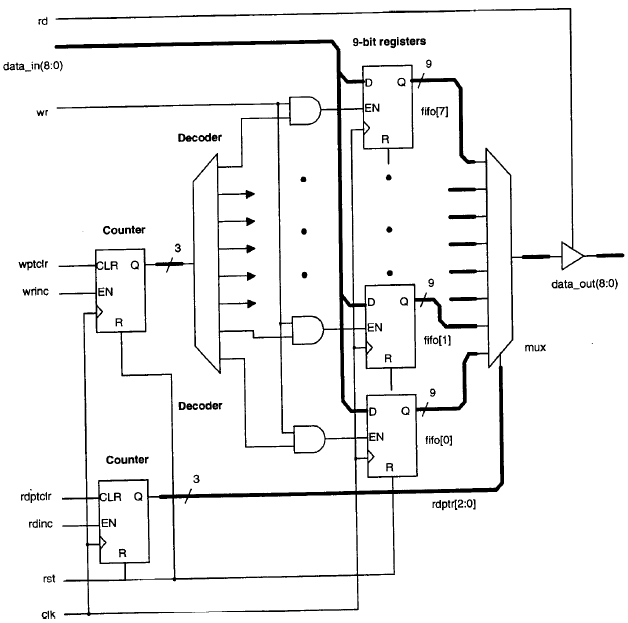
Il listato riportato di seguito illustra un modo di implementare la FIFO che utilizza la progettazione gerarchica e strutturale.


Progetto di macchine a stati finiti
In VHDL descrivere il comportamento di una macchina a stati finiti è solo un problema di tradurre il diagramma a stati in una serie di istruzioni CASE-WHEN e IF-THEN-ELSE, come verrà mostrato nell’esempio illustrato di seguito.
Si vuole descrivere un controller che viene utilizzato per abilitare e disabilitare i segnali di write enable (we) e output enable (oe) di un buffer di memoria durante la fase di lettura e scrittura.
I segnali ready e read_write sono le uscite di un microprocessore e gli ingressi del controller. Una nuova transizione inizia quando il segnale ready viene posto a ‘1’. Un ciclo di clock dopo l’inizio della transizione il valore del segnale read_write determina se effettuare una transizione di lettura o scrittura.
Se read_write viene posto uguale a ‘1’, allora si esegue un ciclo di lettura, altrimenti si esegue un ciclo di scrittura.
Un ciclo viene completato quando ready viene posto a ‘1’, dopo di che può iniziare una nuova transizione.
Write enableviene posto a ‘1’ durante il ciclo di scrittura e output enable viene posto a ‘1’ durante un ciclo di lettura.Nella figura che segue viene riportato il diagramma a bolle del controller.
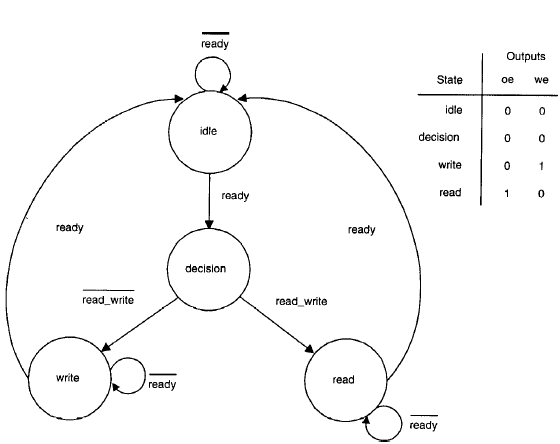
Metodologia di progetto tradizionale.
Con il metodo di progetto tradizionale, il primo passo è quello di disegnare il diagramma dal quale ricavare la tabella degli stati.
E’ possibile quindi fare l’assegnamento degli stati e creare una tabella di transizione degli stati da cui si possono determinare le equazioni che determinano lo stato successivo e le uscite in base ai tipi di flip flop utilizzati per l’implementazione.
La figura del diagramma a bolle (o diagramma degli stati) è mostrata sopra. In questa macchina non ci sono degli stati equivalenti.
E’ possibile combinare la tabella di assegnamento degli stati con la tabella di transizione degli stati, come è riportato nella figura sotto.
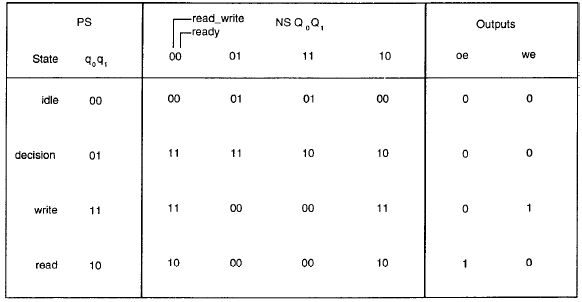
L’assegnamento degli stati è elencato nella colonna present state (PS). Si vuole utilizzare il minor numero possibile di registri per gli stati, cioè due.
La colonna next state (NS) mostra la transizione dallo stato presente verso lo stato successivo in base al valore dei due ingressi read_writee ready.
Le uscite sono riportate nella colonna più a destra.E’ possibile determinare ora l’equazione dello stato successivo per ognuno dei due bit di stato.
Nelle equazioni mostrate, Q1 e Q0 rappresentano i valori dello stato successivo, e q1e q0rappresentano i valori dello stato presente.
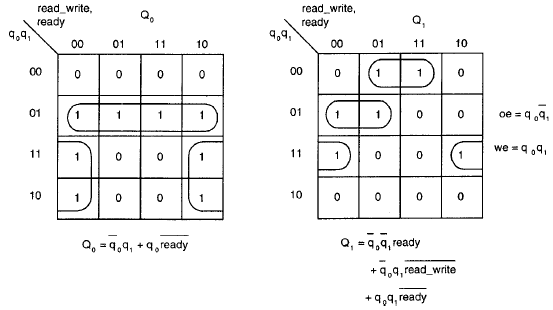
Le mappe di Karnaugh possono essere generate facilmente dalla tabella delle transizioni: ogni riga corrisponde ad uno stato, ogni colonna corrisponde ad una combinazione degli ingressi, e gli ingressi nella mappa di Karnaugh corrispondono ai valori di Q1 e Q0 trovati nella tabella delle transizioni.
Le mappe di Karnaugh vengono poi utilizzate per trovar le equazioni minime assumendo che si utilizzino flip flop di tipo D.
Le uscite sono funzioni solo dello stato presente (macchina di Moore).
Le macchine a stati finiti in VHDL.
Il diagramma degli stati mostrato precedentemente può essere facilmente tradotto in VHDL senza dover effettuare l’assegnamento degli stati, generare la tabella di transizione degli stati, o determinare le equazioni che individuano lo stato successivo in base al tipo di flip flop disponibile.
In VHDL ogni stato può essere tradotto in un caso mediante una istruzione CASE WHEN.
La transizione degli stati può essere specificata mediante una serie di istruzioni IF-THEN-ELSE. Per esempio, per tradurre in VHDL un diagramma degli stati si inizia definendo un tipo enumerativo, formato dal nome degli stati, e dichiarando due segnali del tipo:
![]()
L’operazione successiva da fare è quella di creare un processo.
Next_state viene determinato tramite una funzione di present_state e degli ingressi (readye read_write). Così il processo deve essere sensibile a questi segnali:

All’interno del processo vengono descritte le transizioni della macchina a stati finiti.
Viene aperta una istruzione CASE-WHEN e specificato il primo caso (condizione WHEN), cioè lo stato di idle. Per questo caso, si specificano le uscite definite nello stato di idle e le transizioni che partono da esso.

Ci sono due opzioni in questo caso (cioè, quando present_stateè idle): (1) la transizione allo stato decisionse ready e uguale a ‘1’ oppure (2) rimanere nello stato di idle. In questo caso la condizione di ELSE non è richiesta perché viene utilizzata la memoria implicita e lo stato next_state rimane lo stesso. La codifica degli altri stati viene effettuata nello stesso modo: per ogni stato viene creato un ramo nell’istruzione CASE (WHEN state_name=>), si specifica quali sono le uscite dello stato, e si definisce la transizione agli altri stati con un’istruzione IF -THEN-ELSE.

Il processo mostrato sopra indica che l’assegnamento di next_state è basato su present_state e sugli ingressi correnti, ma non indica quando next_state diventa present_state.
Questo avviene in modo sincrono, sul fronte di salita del clock, come indicato in un secondo processo:
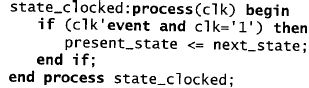
Il codice completo della macchina a stati finiti è il seguente:

Memory controller.
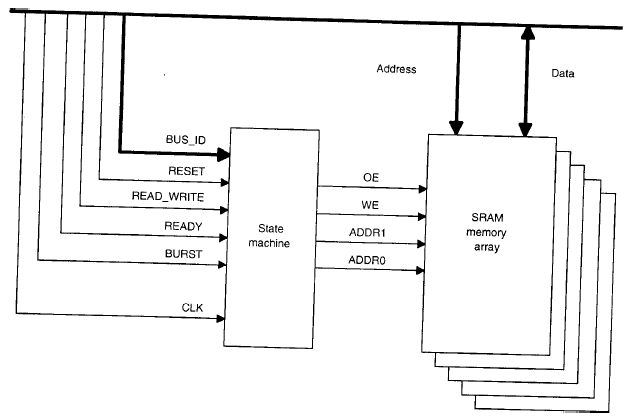
Il memory controller mostrato nella figura sopra, ha il seguente funzionamento: altri dispositivi sul bus iniziano un accesso al buffer di memoria identificandolo sul bus con il suo indirizzo, F3 in esadecimale. Un ciclo di clock dopo, il segnale di read_write viene messo a ‘1’ per indicare una lettura dal buffer di memoria; oppure viene messo a ‘0’ per indicare una scrittura sul buffer di memoria. Se l’accesso alla memoria è una lettura, la lettura potrebbe essere di una sola parola o di un burst di quattro parole. La lettura di un burst è indicata mettendo a ‘1’ il segnale burst durante il primo ciclo di lettura, dopo di che il controller accede a quattro locazioni di memoria dal buffer. Le locazioni consecutive sono accedute mettendo il segnale ready a ‘1’. Il controller mette oe(output enable) a ‘1’ al buffer di memoria durante una lettura, e incrementa i due bit più bassi dell’indirizzo durante una lettura a burst. La scrittura nel buffer di memoria è sempre una scrittura di una singola parola, mai di un burst. Durante una scrittura, we viene messo a ‘1’, permettendo a data di essere scritto nella locazione di memoria specificata da address. Gli accessi in lettura e scrittura sono completati quando il segnale ready viene messo a ‘1’.
La figura successiva mostra il diagramma degli stati del memory controller.
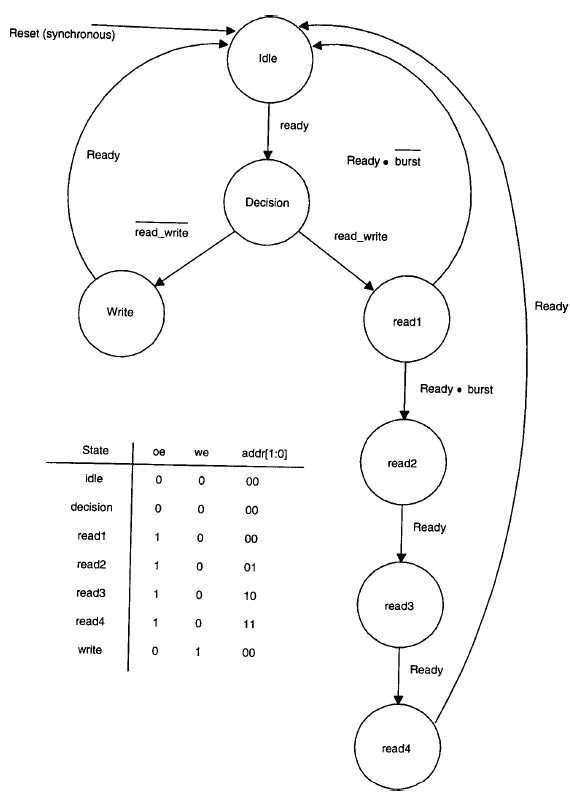
Il diagramma degli stati può essere facilmente tradotto in una serie di istruzioni CASE-WHEN come segue (per ora non viene considerato un reset sincrono):

Reset sincrono un una macchina a stati finiti con due processi.
Questa macchina a stati finiti richiede un reset sincrono. Al posto di specificare la transizione di reset nello stato di idle in ogni ramo dell’istruzione CASE, è possibile includere un’istruzione IF-THEN-ELSE all’inizio del process per fare in modo che la macchina entri nello stato di idle se il segnale di reset viene messo a ‘1’. Se il segnale di reset è a ‘0’, allora avvengono le transizioni di stato normali della macchina, come specificato nell’istruzione CASE. Nell’istruzione IF-THEN-ELSE è necessario specificare anche come si vuole che siano le uscite (oe, wee addr) se il segnale di reset viene messo a ‘1’. Se non vengono specificate le uscite in questa condizione, allora si ottiene l’effetto di memoria implicita: verranno creati dei latch per assicurare che quando il reset viene messo a ‘1’, le uscite mantengano il loro valore. Dato che, in questo caso, non si vuole che siano creati dei latch, viene specificato il valore don’t care quando il segnale di reset viene messo a ‘1’.
Il codice richiesto per il reset è il seguente:

Diversamente, la condizione di reset potrebbe essere messa dopo l’istruzione CASE, come ultima istruzione nel process state_comb. In questo modo, potrebbe essere una semplice istruzione IF-THEN e sarebbe necessaria solo la transizione dello stato. Non è più richiesta la definizione del valore delle uscite. Il codice richiesto in questo caso è:

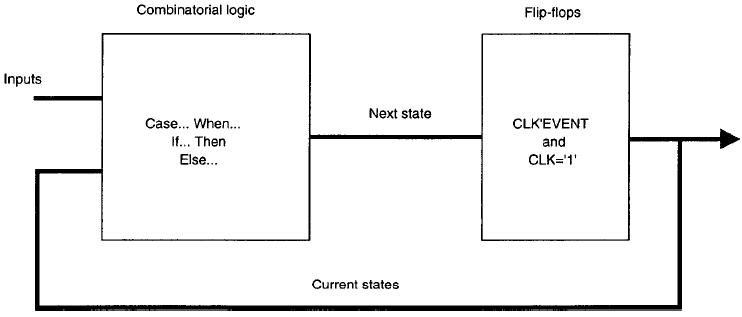
Il codice completo del memory controller è mostrato nel listato sotto:

Il listato riportato nella pagina precedente descrive una macchina a stati finiti con due processi. Un processo che descrive la logica combinatoria, e un altro che descrive la sincronizzazione delle transizioni di stato con il clock, come illustrato nella figura seguente.
Reset asincrono.
Se è necessario utilizzare un reset asincrono invece che uno sincrono, allora è possibile utilizzare uno schema di reset come quello riportato nel seguente listato:

Se il segnale di reset è utilizzato solo durante l’inizializzazione o i malfunzionamenti del sistema, allora è preferibile utilizzare un reset di tipo asincrono. Questo principalmente perché un reset sincrono richiede risorse del dispositivo addizionali, inoltre elimina la possibilità di introdurre accidentalmente la memoria implicita.
Il codice nel listato riportato sotto è funzionalmente equivalente a quello riportato nel listato precedente, però utilizza solamente un processo per descrivere la transizione tra gli stati e la sincronizzazione delle transizioni con il clock. Una serie di istruzioni concorrenti addizionali sono utilizzate per descrivere il comportamento delle uscite.

Area, velocità e utilizzazione delle risorse del dispositivo.
Di seguito vengono illustrate quattro tecniche per generare l’uscita delle macchine a stati finiti per le macchine di Moore:
- decodifica dell’uscita dai bit di stato in modo combinatorio•decodifica dell’uscita in registri di uscita paralleli
- codifica dell’uscita all’interno dei bit di stato
- codifica one hot Ognuna di queste tecniche produce un’implementazione logica con differenti caratteristiche di temporizzazione.
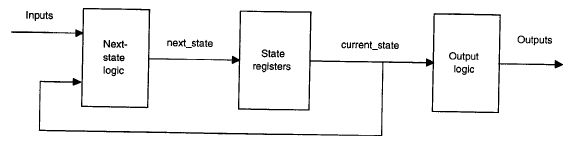
Decodifica dell’uscita dai bit di stato in modo combinatorio.
I listati precedenti descrivono le uscite che devono essere decodificate dallo stato presente dei bit di stato come riportato nella figura sotto. Questa decodifica combinatoria può richiedere livelli di logica addizionali, rendendo così più lenta la propagazione dall’uscita dei bit di stato ai segnali di uscita del dispositivo.
Decodifica dell’uscita in registri di uscita paralleli
Un modo per assicurare che le uscite della macchina a stati finiti arrivino ai pin del dispositivo più rapidamente è decodificare le uscite dai bit di stato prima che i bit di stato vengano memorizzati, e quindi immagazzinare l’informazione decodificata in alcuni registri. Questo può essere fatto sia con la descrizione della macchia a stati finiti con un processo che con due processi.
In entrambi i casi, l’assegnamento a addr deve essere descritto fuori dal processo in cui sono definite le transizioni di stato. Invece di utilizzare le informazioni del present_state per determinare il valore di addr, viene utilizzata l’informazione di next_state per determinare come dovrebbe essere il valore di addr durante il successivo ciclo di clock. Il concetto di immagazzinare il valore delle uscite in base al valore di next_state è illustrato nella figura sotto.
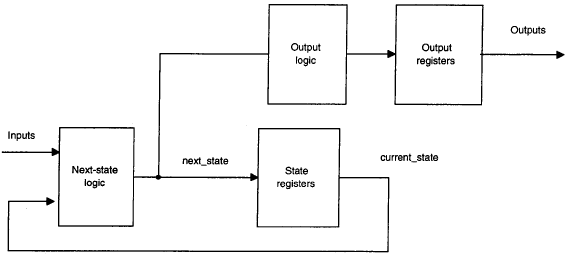
Per modificare il progetto del memory controller per includere la decodifica delle uscite in registri di uscita paralleli, il listato precedente viene modificato come riportato di seguito. I commenti sono utilizzati per indicare dove ci sono differenze nel codice.


In questo progetto è stato dichiarato un segnale addizionale: addr_d. Questo viene utilizzato per decodificare in modo combinatorio come dovrebbe essere il valore di addr il ciclo di clock successivo. Questo viene fatto rimuovendo l’istruzione di assegnamento del segnale addr dal istruzione CASE, e inserendo un’istruzione di assegnamento dei segnali WITH-SELECT-WHEN, in cui il segnale di selezione è next_state. Poi, il segnale addr_d viene memorizzato nel segnale addr sul fronte di salita del clock. Tutto questo viene descritto nel processo state_clocked. L’istruzione WITH-SELECT-WHEN non è necessario che sia posta tra i due processi potrebbe essere messa prima o dopo di loro.
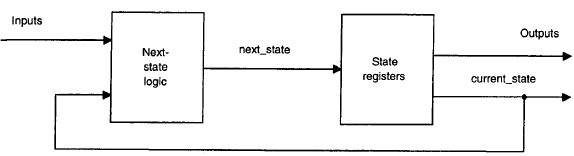
Codifica dell’uscita con i bit di stato
Un contatore è un esempio di una macchina a stati finiti nella quale le uscite sono i bit di stato. Questo metodo potrebbe funzionare meglio dei precedenti in alcuni casi particolari, ma richiede una scelta accurata della codifica degli stati: l’uscita deve corrispondere al valore memorizzato nel registro degli stati, come mostrato nella figura sotto.
Questo approccio rende la progettazione più complicata da comprendere e cambiare, così è raccomandata solo per i casi che richiedono ottimizzazioni di area e prestazioni non fornite dagli strumenti di sintesi, o automaticamente dalle direttive di implementazione.
Codifica one-hot
Questa è una tecnica che utilizza n flip flop per rappresentare una macchina a stati finiti con n stati. Ogni stato ha un suo proprio flip flop, e solo un flip flop è “hot” (cioè ha memorizzato un ‘1’) ogni intervallo di tempo. Uno dei vantaggi della codifica “one hot” è che il numero di porte richieste per decodificare l’informazione degli stati per le uscite e per la transizione allo stato successivo e molto minore del numero di porte richiesto a questo scopo dagli altri metodi di codifica. Questa differenza nella complessità diventa più evidente al crescere del numero degli stati. A seconda dell’architettura del dispositivo utilizzato, una macchina a stati finiti con codifica one hot potrebbe richiedere meno risorse del dispositivo per l’implementazione del progetto. Una logica per determinare lo stato successivo più semplice richiede meno livelli di logica tra i registri di stato, permettendo così frequenze di funzionamento più alte. La codifica one hot non è sempre la miglior soluzione, principalmente perché richiede più flip flop che una macchina a stati finiti codificata in modo sequenziale. In generale, la codifica one hot è più utile quando l’architettura del dispositivo programmabile che si vuole utilizzare contiene un numero relativamente elevato di registri e poca logica combinatoria tra ogni registro. Per esempio, la codifica one hot risulta più utile per le macchine a stati finiti implementate dentro alle FPGA, che generalmente hanno una densità di flip flop più elevata che le CPLD ma un minor numero di porte logiche per flip flop. Finora si è discusso di che cosa è la codifica one hot e quando conviene utilizzarla, vediamo ora come descrivere una macchina a stati finiti con la codifica one hot. Fortunatamente, la codifica one hot richiede pochi o nessun cambiamento al codice sorgente, ma dipende dal software di sintesi che viene utilizzato. Molti software per la sintesi permettono di utilizzare alcune direttive di sintesi nella forma di istruzioni VHDL, o di opzioni GUI (come avviene nel software Foundation Express). Generare le uscite per una macchina a stati finiti con codifica one hot è analogo a generare le uscite per macchine in cui le uscite sono decodificate dai registri di stato. La decodifica è abbastanza semplice perché gli stati sono solo dei bit singoli e non un intero vettore. La logica di uscita consiste di una porta OR perché le macchine di Moore hanno le uscite che sono funzioni solo dello stato, e tutti gli stati in una macchina a stati finiti con codifica one hot sono rappresentati da un bit. In una FPGA, il ritardo associato ad una porta OR è tipicamente accettabile ed è un miglioramento rispetto alle decodifiche dell’uscita che utilizzano un intero vettore di stato.
Macchine di Mealy
Finora sono state trattate solo le macchine di Moore (figura sotto a) in cui le uscite sono funzioni solamente dello stato corrente. Le macchine di Mealy (figura sotto b) possono avere uscite che sono funzioni dello stato presente e dei segnali presenti in ingresso, come illustrato nella figura sotto.
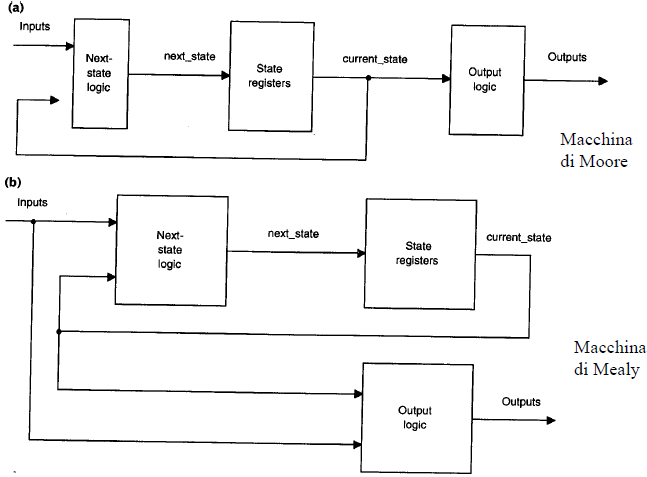
Il lavoro addizionale che è 19necessario per descrivere le macchine di Mealy rispetto alle macchine di Moore è minimo. Per implementare una macchina di Mealy occorre semplicemente descrivere un’uscita come funzione sia dei bit di stato che degli ingressi. Per esempio, se vi è un ingresso addizionale al memory controller chiamato write_mask che quando vale ‘1’ non consente a we di essere abilitato, è possibile descrivere la logica per we come

Questo rende we un’uscita di Mealy.